
An example and a surprise
%pylab inline --no-import-all
florence, shelly = np.loadtxt('times.dat', delimiter=',')
counts, bins, patches = plt.hist(florence,bins=50,alpha=0.2, label='Flo-Jo')
counts, bins, patches = plt.hist(shelly,bins=bins,alpha=0.2, label='Shelly-Ann')
plt.legend()
plt.xlabel('times (s)')

np.mean(florence), np.mean(shelly)
np.std(florence),np.std(shelly)
mean_q = np.mean(shelly)-np.mean(florence)
sigma_q = np.sqrt(np.std(florence)**2+np.std(shelly)**2)
f_guess = np.random.normal(np.mean(florence),np.std(florence),10000)
s_guess = np.random.normal(np.mean(shelly),np.std(shelly),10000)
toy_difference = s_guess-f_guess
Make Toy data
#toy_difference = np.random.normal(mean_q, sigma_q, 10000)
counts, bins, patches = plt.hist(toy_difference,bins=50, alpha=0.2, label='toy data')
counts, bins, patches = plt.hist(toy_difference[toy_difference<0],bins=bins, alpha=0.2)
norm = (bins[1]-bins[0])*10000
plt.plot(bins,norm*mlab.normpdf(bins,mean_q,sigma_q), label='prediction')
plt.legend()
plt.xlabel('Shelly - Florence')
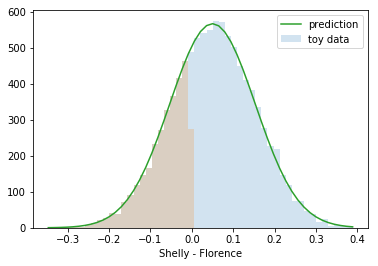
# predict fraction of wins
np.sum(toy_difference<0)/10000.
#check toy data looks like real data
counts, bins, patches = plt.hist(f_guess,bins=50,alpha=0.2)
counts, bins, patches = plt.hist(s_guess,bins=bins,alpha=0.2)
counts, bins, patches = plt.hist(shelly-florence,bins=50,alpha=0.2)
counts, bins, patches = plt.hist((shelly-florence)[florence-shelly>0],bins=bins,alpha=0.2)
plt.xlabel('Shelly - Florence')
1.*np.sum(florence-shelly>0)/florence.size
plt.scatter(f_guess,s_guess, alpha=0.01)
plt.scatter(florence,shelly, alpha=0.01)
plt.hexbin(shelly,florence, alpha=1)
Previously we learned propagation of errors formula neglecting correlation:
$\sigma_q^2 = \left( \frac{\partial q}{ \partial x} \sigma_x \right)^2 + \left( \frac{\partial q}{ \partial y}\, \sigma_y \right)^2 = \frac{\partial q}{ \partial x} \frac{\partial q}{ \partial x} C_{xx} + \frac{\partial q}{ \partial y} \frac{\partial q}{ \partial y} C_{yy}$
Now we need to extend the formula to take into account correlation
$\sigma_q^2 = \frac{\partial q}{ \partial x} \frac{\partial q}{ \partial x} C_{xx} + \frac{\partial q}{ \partial y} \frac{\partial q}{ \partial y} C_{yy} + 2 \frac{\partial q}{ \partial x} \frac{\partial q}{ \partial y} C_{xxy} $
# covariance matrix
cov_matrix = np.cov(shelly,florence)
cov_matrix
# normalized correlation matrix
np.corrcoef(shelly,florence)
# q = T_shelly - T_florence
# x = T_shelly
# y = T_florence
# propagation of errors
cov_matrix[0,0]+cov_matrix[1,1]-2*cov_matrix[0,1]
mean_q = np.mean(shelly)-np.mean(florence)
sigma_q_with_corr = np.sqrt(cov_matrix[0,0]+cov_matrix[1,1]-2*cov_matrix[0,1])
sigma_q_no_corr = np.sqrt(cov_matrix[0,0]+cov_matrix[1,1])
counts, bins, patches = plt.hist(shelly-florence,bins=50,alpha=0.2)
counts, bins, patches = plt.hist((shelly-florence)[florence-shelly>0],bins=bins,alpha=0.2)
norm = (bins[1]-bins[0])*10000
plt.plot(bins,norm*mlab.normpdf(bins,mean_q,sigma_q_with_corr), label='prediction with correlation')
plt.plot(bins,norm*mlab.normpdf(bins,mean_q, sigma_q_no_corr), label='prediction without correlation')
plt.legend()
plt.xlabel('Shelly - Florence')
1.*np.sum(florence-shelly>0)/florence.size
np.std(florence-shelly)
np.sqrt(2.)*0.73
((np.sqrt(2.)*0.073)**2-0.028**2)/2.
.073**2
np.std(florence+shelly)
np.sqrt(2*(np.sqrt(2.)*0.073)**2 -0.028**2)