I'm pretty excited about this alternate approach to multimodal inference that replaces the standard high-dimensional, task-agnostic representations used in multimodal foundation models with task-dependent scalar functions. The paper isn't ready for publication and my experiments are still running, but I'm excited to share the idea as it's a big departure from the conventional approach.
Here's a link to the draft paper. (Note, I used ChatGPT to help me with the initial draft, and I've found some other relevant work as noted in the footnotes.)
Abstract Multimodal foundation models integrate heterogeneous data sources into unified representations. This is particularly powerful in scientific settings as these unified representations can be used as the input to downstream statistical inference tasks such as hypothesis testing, parameter estimation, or other forms of inference of underlying phenomena. Typically, contrastive learning or masked objectives are used to train task-agnostic representations followed by task-specific fine-tuning or the addition of task-specific heads. We propose an alternative framework for multimodal inference in which the task-specific training is applied to each modality individually. We show that the output representation for each modality can be reduced to a scalar function of the parameters and that these scalars can be aggregated additively without degrading performance. We show that, under conditional independence across modalities, this architecture enables permutation-invariant fusion, independent training of modality-specific encoders, and append-only extensibility. For regression tasks, predictive estimates can be extracted by passing this scalar function to a differentiable optimization layer. We show that in the limit of many observations, the resulting estimators achieve optimal properties. These results suggest that when representations are conditioned on the inferential context, high-dimensional multimodal embeddings are unnecessary: one scalar function per modality suffices.
Introduction
Multimodal foundation models are increasingly viewed as a pathway toward scientific discovery, where diverse data sources are combined to infer underlying laws governing complex systems. Notationally, we will use \(\theta\) to represent a discrete index or the continuous parameters of a family of scientifically-motivated generative models for the data. In many such settings, this shared parameter vector \(\theta\) determines the distribution of multiple observational modalities \(x_1, \dots, x_M\), each providing a complementary view of the same phenomenon.
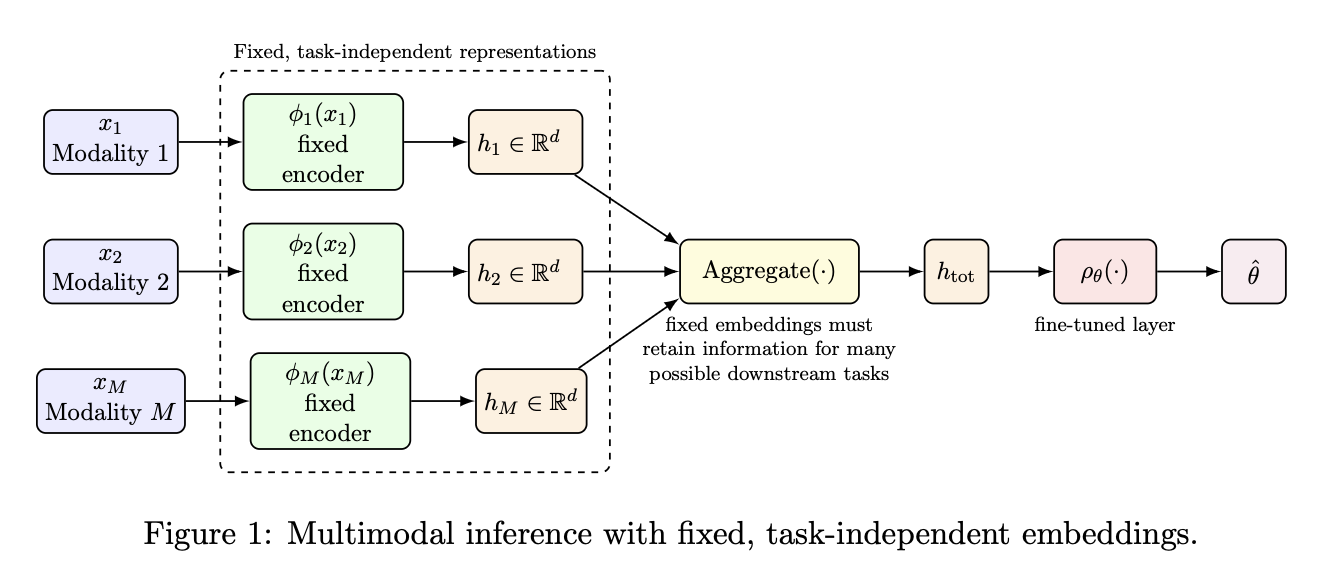
A central challenge is how to combine information across modalities in a way that is both efficient and scalable. Existing approaches typically rely on high-dimensional shared embeddings or aggregation strategies, which must retain information relevant across many potential downstream tasks (or relevant for predicting the parameter values \(\theta\) that correspond to various hypotheses for the data generating process). While these approaches have demonstrated strong empirical performance, they raise fundamental questions about the nature and dimensionality of representations required for optimal inference.
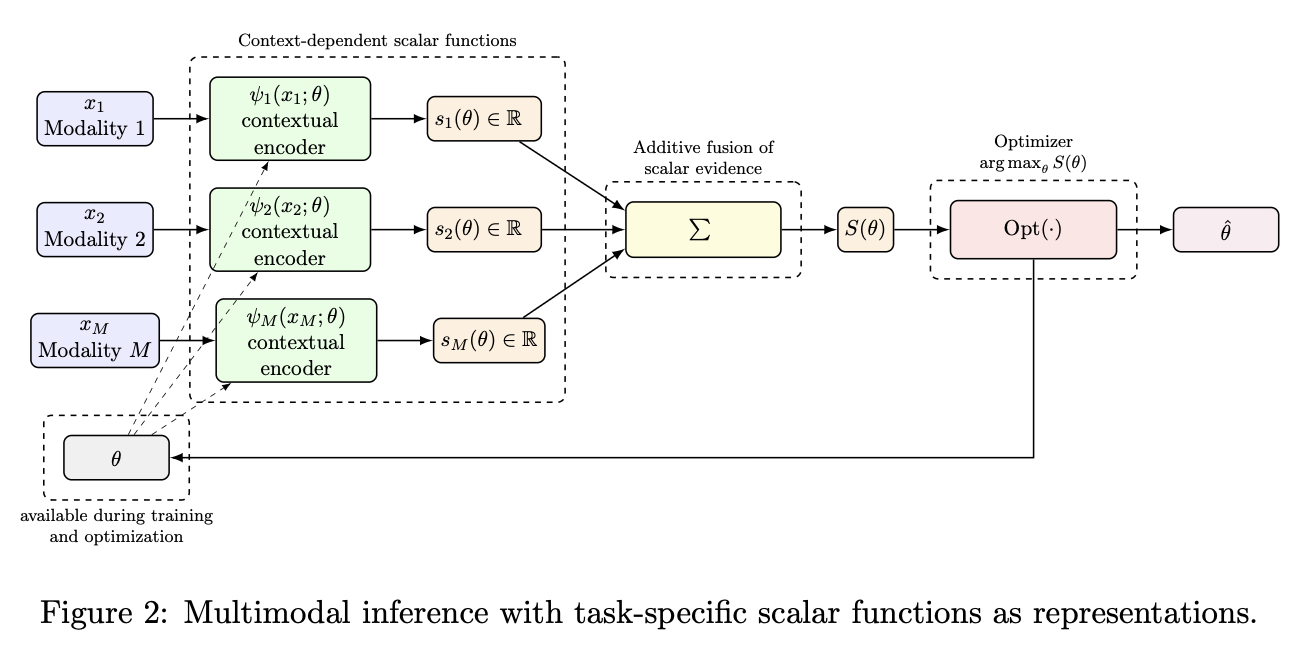
In this work, we propose an alternative perspective in which multimodal inference is reduced to the aggregation of scalar, context-dependent evidence contributions. Rather than learning fixed high-dimensional representations that are independent of the downstream inferential task, we embrace the opposite extreme in which each modality has a context-dependent encoder that depends explicitly on the parameter \(\theta\) under consideration. This leads to a formulation in which each modality contributes a single scalar-valued function, and these functions are combined additively. We show that this formulation leads to estimators \(\hat{\theta}\) that achieve the best possible precision allowed by the data, while also providing a simple and extensible architecture for multimodal learning.
The main contributions of this work are:
- A formulation of multimodal inference based on contextual scalar bottlenecks
- A demonstration that additive scalar aggregation is sufficient for optimal inference under conditional independence
- A modular training strategy enabling independent optimization of modality-specific encoders
- An append-only architecture supporting seamless integration of new modalities and additional data
Traditional Approach Based on Aggregation Task-Independent Embeddings
Proposed approach Based on Context-Dependent Scalar Functions as Representations